About
I've been making notes on CS258 over the summer, as it's one of the few modules with material I can access early. I'm using Fundamentals of Database Systems 7th Edition by R. Elmasri and S. B. Navathe to supplement these notes, and although I've tried to only look at the relevant topics, I'm not sure what is and isn't examinable on the textbook.
Also, I'm a big fan of diagrams. It's too much of a faff to actually make diagrams, so I'm just going to scribble them with Microsoft paint like I did with the rats I lied. I made diagrams in MS paint and then got angry because they didn't look as good as I wanted, so I whipped out Clip Studio and... drew them again, but with more effort (probably more effort than making actual diagrams, as well).
Introduction to Databases
A database management system(DBS or DBMS) is a computerised system that enables the user to create and manage a database.
On DBS
The DBS allows databases to be defined, constructed, manipulated, shared and secured between various users and applications:
- Define: Specifying the types, structures, and constraints of data to be stored.
- Construct: Storing the data in a storage medium controlled by the DBS.
- Manipulate: Updating data, accessing and retrieving data, etc.
- Share: Allowing multiple users and programs to access simultaneously.
- Secure: Protecting against malicious attacks and software/hardware failures.
The Three-Schema Architecture
The goal of the three-schema architecture is to separate user applications from the physical database. It is composed of three levels:
- The internal level has an internal schema, which describes the physical storage structure of the database. It uses a physical data model and describes details of data storage and access paths for the database.
- The conceptual level has an conceptual schema which hides the physical details and instead describes the stucture of the database in a logical way, focusing on describing entities, data types, relationships, user operations, and constraints.
- The external/view level includes a number of external schemas or user views. Each external schema only describes the part of the database that is relevant to a particular user group, and hides the rest.
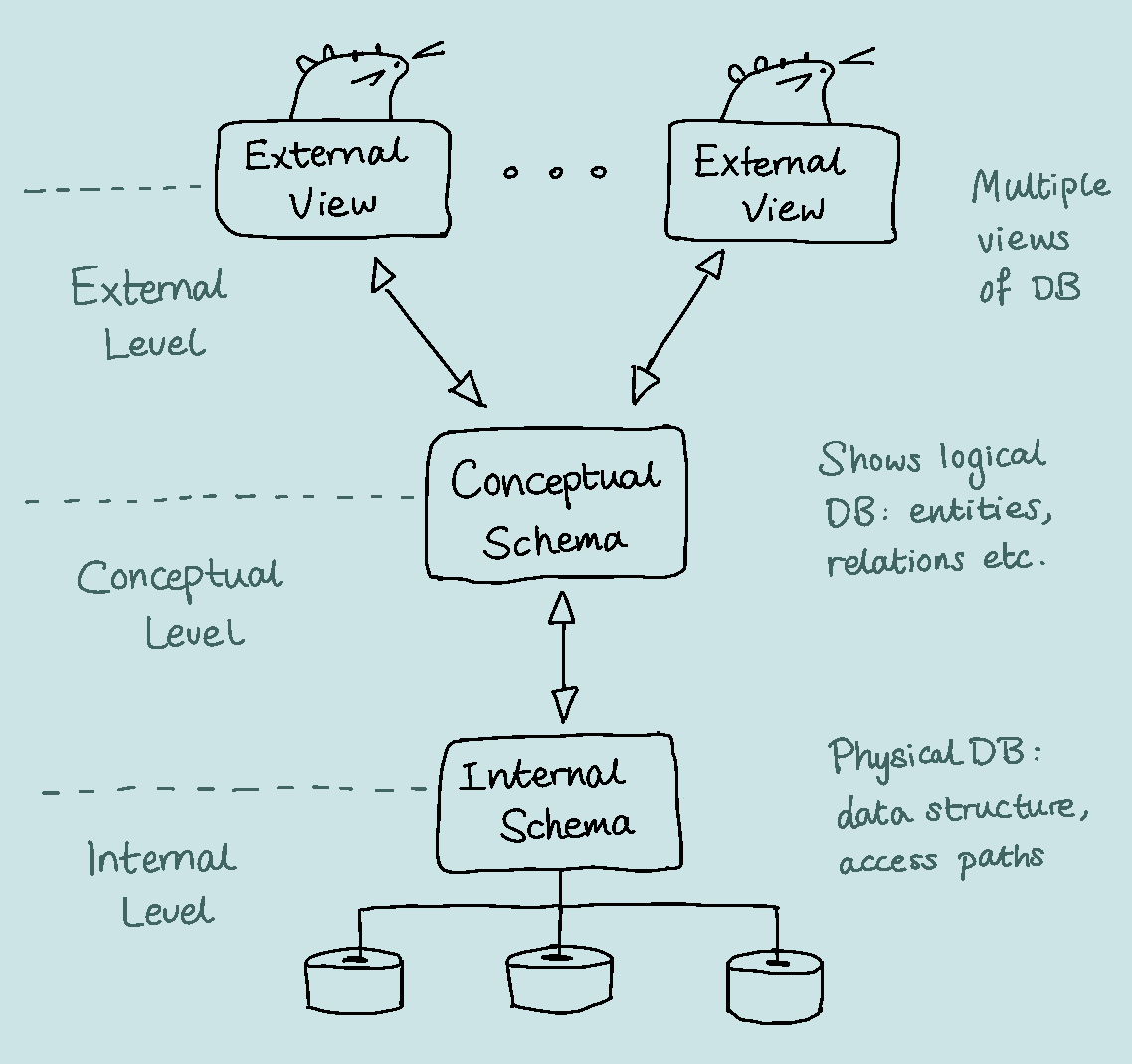
The three-schema architecture can be used to explain the concept of data independence, defined as the capacity to change the schema at one level of a database system without having to change the schema at the next higher level. We can define two types of data independence:
- Logical data independence is the capacity to change the conceptual schema without having to change external schemas. This means that when the database is expanded, reduced, or when some of its constraints are changed, the external schemas that refer to only the remaining data should not be affected.
- Physical data independence is the capacity to change the internal schema without having to change the conceptual schema. The internal schema might need to be changed to reorganise physical files, such as adding additional access structures to improve the performance of retrieval or update.
The Relational Data Model
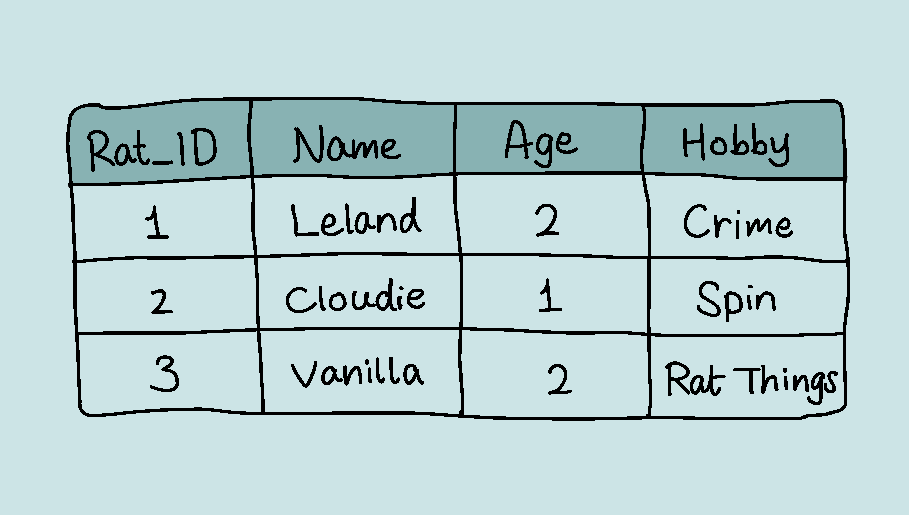
On Relations
We can think of a relation as a table of values. In this table, a row (formally a tuple) typically represents a real-world entity, and each column represents a specific attribute or type of data across all rows.
Each attribute has a domain. This is the set of valid values for that attribute. For example, the domain of Age is any integer above 0. Of course, there aren't any rats that live forever (that we know of) (for now), so we might also want to give it an upper limit.
Each row in a table must be uniquely identifiable so that we can reference to them individually. To do this, we allocate keys to the rows such that each key is distinct. Sometimes we assign arbitrary IDs to achieve this, and this is called an artificial key, or surrogate key.

Formally, a relation is an unordered set of tuples.
The schema of a relation is denoted by R(A1, A2, ..., An), where R is the name of the relation, and A1-An are the attributes of the relation. For example, the schema of the table about would be RAT(Rat_ID, Name, Age, Hobby)
The relation state r, also denoted by r(R) is:
- The set of tuples currently in the relation;
- A subset of the Cartesian product of the domains of its attributes.
To put it in plain words, r is an actual set of tuples with specific attributes.
Formally, r = {t1, t2, ..., tm}, where each t = <v1, v2, ..., vn>. Each value vi has 1 ≤ i ≤ n, and is an element of dom (Ai) or a special NULL value. The ith value in tuple t is referred to as t[Ai].
The term relation intension can also be used for the schema R - it is the permanent part of the relation. The term relation extension is used for the state r(R), and is the set of tuples that are in the relation at any given instance. These tuples can be created, updated, and destroyed.
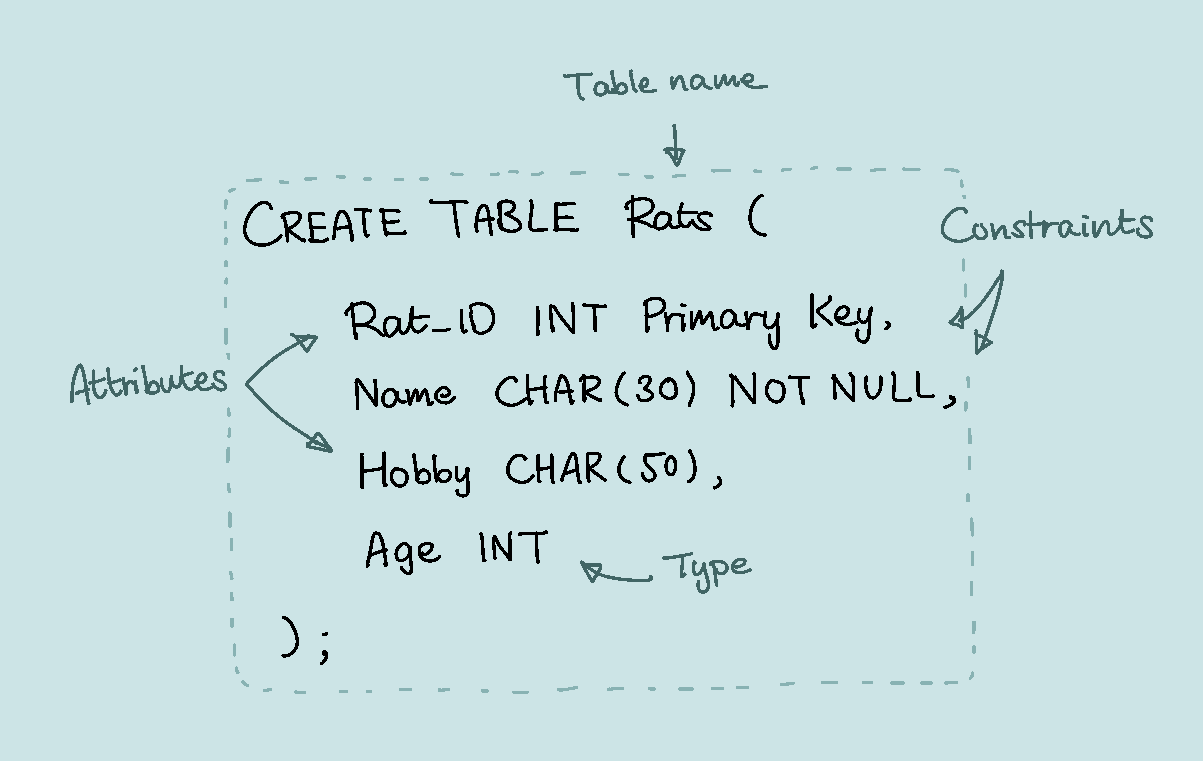
SQL Example
The following diagram is an example of what the structure of the above table could look like in SQL:
Constraints of the Relational Data Model
Key Constraints
A superkey SK of R is a subset of attributes of R, such that:
- For any two distinct tuples t1 and t2 in r(R), t1[SK] ≠ t2[SK].
Essentially this means that the superkey is a group of attributes that uniquely defines a tuple!
A candidate key K of R is a minimal superkey. This means:
- If we remove any attribute from K, it is no longer a superkey.
If a relation has more than one candidate key, we arbitrarily choose one to be the primary key.
Entity Integrity Constraints
(Any of) The primary key attributes cannot be NULL in any tuple of r(R).
- We wouldn't be able to identify the tuple otherwise!
An attribute of R might not be allowed to be NULL.
- Such as the colour of rat, as every rat must have a colour.
Referential Integrity Constraints
This refers to cross-table relationships. An example:
- R1: Rats(rat_id, name, age, hobby)
- R2: Rat_Houses(house_id, rat_id, model, size)
A query could ask about the names of rats housed in a particular house. This information is spread out between the two tables, and this is fundamental to R-DMBS design.
A set of attributes FK from R2 is a foreign key that references relation R1 if:
- Attribute(s) in the FK from R2 have the same domain as the attribute(s) in the primary key PK of R1.
- A value of FK in R1 must either refer to the value of a PK in R2, or be NULL.
Domain Constraints
- Defines the type of values in an attribute. e.g. Age must be an integer.
- Note that values could also be NULL, if allowed. e.g. Phone number, spouse name for single persons...
Semantic Attribute Integrity Constraints
These depends on the exact semantics, e.g.
- Rat age ≥ 0
- House size > 1 (rats are social animals!)
Possible Violations by Operation
INSERT
- Domain: attribute value not in domain
- Key: key value already exists
- Referential: foreign key does not refer to any existing primary keys
- Entity: primary key value is NULL
DELETE
- Referential: primary key that was referenced in another table is deleted
UPDATE
- Domain: attribute value not in domain
- Key: key value already exists
- Referential: foreign key does not refer to any existing primary keys
- Entity: any NOT NULL value changed to NULL
Functional Dependencies
X → Y is an assertion about a relation R and two sets of attributes from R.
If X → Y, the values of attribute Y of a tuple depends on values of the X attribute. i.e. If two tuples of R agree on values of all the attributes of X, then they must alos agree on values of attribute of Y.
Looking back on this table, we can see that Name → Hobby, for example. However, it doesn't make much sense to say a rat's hobby depends on its name in real life, so realistically we would assert a key K, often the ID, where K → A for every attribute A. e.g. Rat_ID → {Name, Age, Hobby.}
Claim 1: If K is a superkey, then K → A, for any (subset of) attribute(s) A in R.
- I think this is true.
- In a (legal) table, two tuples will always have different values in their superkey, hence they will never agree.
Claim 2: If X → R (all attributes of relation R), then X is a superkey.
- I think this is true also.
- In a (legal) table, two tuples will never be the exact same. Then, all X must also be different by definition of FDs. Hence, X is a superkey by definition.

